Lindley's paradox
Lindley's paradox is a counterintuitive situation in statistics in which the Bayesian and frequentist approaches to a hypothesis testing problem give opposite results for certain choices of the prior distribution. The problem of the disagreement between the two approaches was discussed in Harold Jeffreys' textbook[1]; it became known as Lindley's paradox after Dennis Lindley called the disagreement a paradox in a 1957 paper[2].
Contents |
Description of the paradox
Consider a null hypothesis H0, the result of an experiment x, and a prior distribution that favors H0 weakly. Lindley's paradox occurs when
- The result x is significant by a frequentist test, indicating sufficient evidence to reject H0, say, at the 5% level, and
- The posterior probability of H0 given x is high, say, 95%, indicating strong evidence that H0 is in fact true.
These results can happen at the same time when the prior distribution is the sum of a sharp peak at H0 with probability p and a broad distribution with the rest of the probability 1 − p. It is a result of the prior having a sharp feature at H0 and no sharp features anywhere else.
Numerical example
We can illustrate Lindley's paradox with a numerical example. Let's imagine a certain city where 49,581 boys and 48,870 girls have been born over a certain time period. The observed proportion (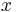 ) of male births is thus 49,581/98,451 ≈ 0.5036. We are interested in testing whether the true proportion (
) of male births is thus 49,581/98,451 ≈ 0.5036. We are interested in testing whether the true proportion (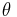 ) is 0.5. That is, our null hypothesis is
) is 0.5. That is, our null hypothesis is 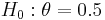 and the alternative is
and the alternative is 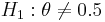 .
.
Bayesian approach
We have no reason to believe that the proportion of male births should be different from 0.5, so we assign prior probabilities 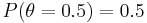 and
and 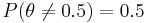 , the latter uniformly distributed between 0 and 1. The prior distribution is thus a mixture of point mass 0.5 and a uniform distribution
, the latter uniformly distributed between 0 and 1. The prior distribution is thus a mixture of point mass 0.5 and a uniform distribution 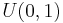 . The number of male births is a binomial variable with mean
. The number of male births is a binomial variable with mean 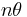 and variance
and variance 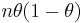 , where
, where 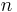 is the total number of births (98,451 in this case). Because the sample size is very large, and the observed proportion is far from 0 and 1, we can use a normal approximation for the distribution of
is the total number of births (98,451 in this case). Because the sample size is very large, and the observed proportion is far from 0 and 1, we can use a normal approximation for the distribution of 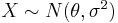 . Because of the large sample, we can approximate the variance as
. Because of the large sample, we can approximate the variance as 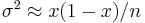 . The posterior probability is
. The posterior probability is
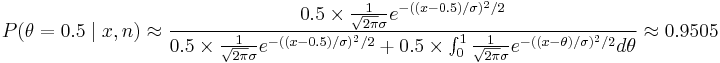 .
.
So we find that there is not enough evidence to reject .
Frequentist approach
Using the normal approximation above, the upper tail probability is
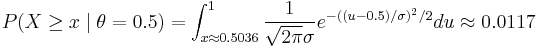 .
.
Because we are performing a two-sided test (we would have been equally surprised if we had seen 48,870 boy births, i.e. 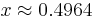 ), the p-value is
), the p-value is 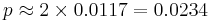 , which is lower than the significance level of 5%. Therefore, we reject .
, which is lower than the significance level of 5%. Therefore, we reject .
The two approaches—the Bayesian and the frequentist—are in conflict, and this is the paradox.
Notes
- ^ Jeffreys, Harold (1939). Theory of Probability. Oxford University Press. MR924.
- ^ Lindley, D.V. (1957). "A Statistical Paradox". Biometrika 44 (1–2): 187–192. doi:10.1093/biomet/44.1-2.187.
References
- Shafer, Glenn (1982). "Lindley's paradox". Journal of the American Statistical Association 77 (378): 325–334. doi:10.2307/2287244. JSTOR 2287244. MR664677.